Data Lake allows to store big data volume that can be used by data scientists and data analysts. Well-Designed Data Lake Architecture is extremely important because it can address many business requirements not met in Data Warehouse solutions.
Advantage of Data Lake
♦ Reduce contact with Data Sources (all data is available in Raw Data layer)
♦ Lower cost of data storage than Data Warehouse (ideal for historical or granular data)
♦ High scalability
♦ Fully independent compute power (data can be processed in parallel by many servers)
Data Lake Architecture
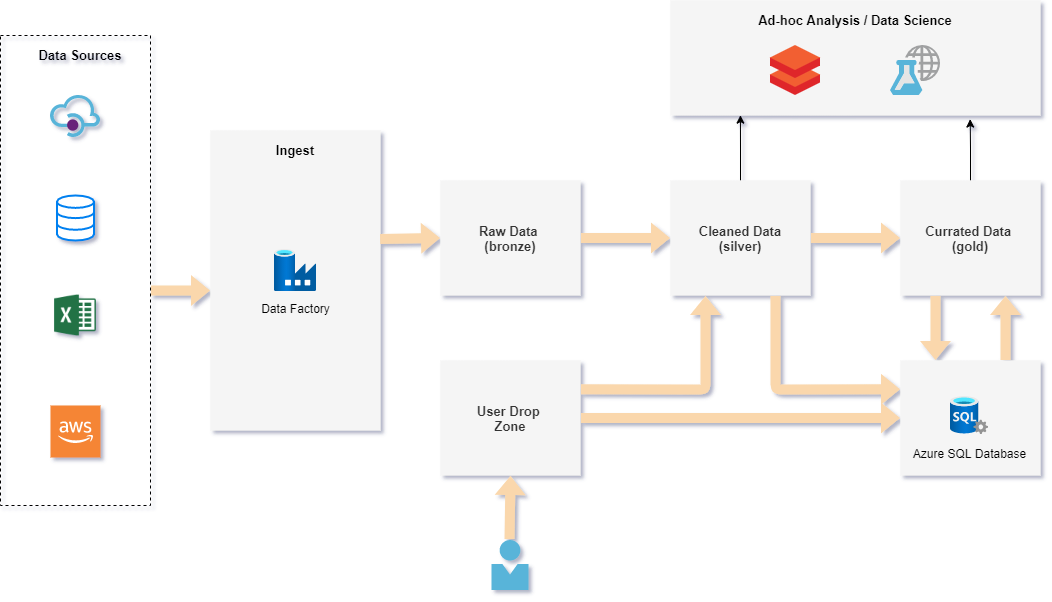
Data Lake Layer Definition
| Bronze | Silver | Gold | |
| File Format | All | Parquet / Delta | Parquet / Delta |
| Transformation | No | Simple | Full |
| Surrogate key | No | No | Yes |
Raw Data (bronze)
Data is either sent from source systems or ingested by Azure Data Factory. Streaming data can be ingested from IoT Hub or Event Hub. Data is stored in native raw format (no data transformation). Instead, the data should be copied from source systems as soon as possible. This layer is usually not shared for analytics purpose.
\Bronze\DataSource\Entity\version\YYYY\MM\DD\file_name_yyymmdd_hhmm.parquet/avro/csv
Cleaned Data (silver)
Silver layer represent a more refined view of data stored in bronze layer. Data is saved in the same, preferred format (eg. Parquet/Delta). Single logical file is cleaned, merged and enriched by User Drop Zone. Data is ready-to-use by data scientists.
\Silver\DataSource\Entity\version\file_name.parquet/delta
Curated (gold)
All data transformations are implemented in this layer. It is ready-to-use by data analysts because data is designed in Star Schema model (similar to Data Warehouse).
\Gold\(Dim_Entity/Fact_Entity)\version\file_name.parquet/delta
Security
Data Lake access can be managed by RBAC (role-based access control) or ACL (access control list).
RBAC allows to control acces either on Data Lake or container level, while ACL can manage single file access control.
Delta Lake
While working on Data Lake Architecture, it is extremely important to review Delta Lake concept that brings ACID transactions to Data Lake. Delta Lake transaction logs provide isolation level, audit history and data versioning. It significantly simplify data integration process.
Delta Lake Features
♦ ACID transactions on Spark
♦ Scalable metadata handling
♦ Streaming and batch unification
♦ Schema enforcement
♦ Time travel
♦ Upserts and deletes
♦ Fully configurable/opitmizable
♦ Structured streaming support
In case od Delta Lake approach, usually there is one more layer called Landing zone where files are uploaded in native raw format. Files stored in Bronze layer are loaded in delta format and append mode instead. Once Bronze layer is updated, files in Landing zone are deleted. It allows to store historical data in the same format (delta) as in other layers.