DBT stands for Data Build Tool. It is open source project (python library) that allows to easily orchestrate data processing in Snowflake, Databricks, Redshift etc.
Advantages of using DBT:
✅ Auto-generated orchestration – DBT identifies dependencies and execute data processing
✅ Testing functionalities – test allows to identify anomalies, nulls etc. The process either warn or fail depending on testing rules.
✅ Standardization of the procedures using macros – materialization simplifies DML statements
✅ SQL automation – macro automates generation of sql statement
✅ Auto-generated documentation – DBT generates documentation by default
Architecture:
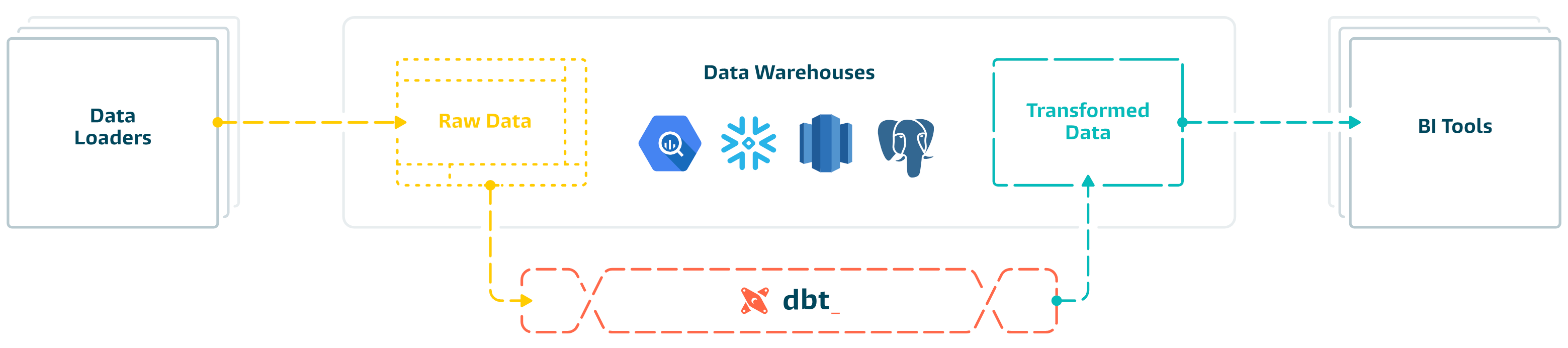
DBT Intro:
DBT Project contains at a minimum:
– Authentication configuration file (profiles.yml)
– DBT Project configuration file (dbt_project.yml)
– Definition of source tables (sources.yml)
– Data Transformation logic saved as select statement in single .sql file (models)
Data Orchestration is executed by one of following command:
– DBT RUN – execute data processing
– DBT TEST – execute data testing
– DBT BUILD – execute both data processing and testing
Demo:
Code can be developed and executed either locally eg. Visual Studio (free) or using DBT WEB UI (paid license) .
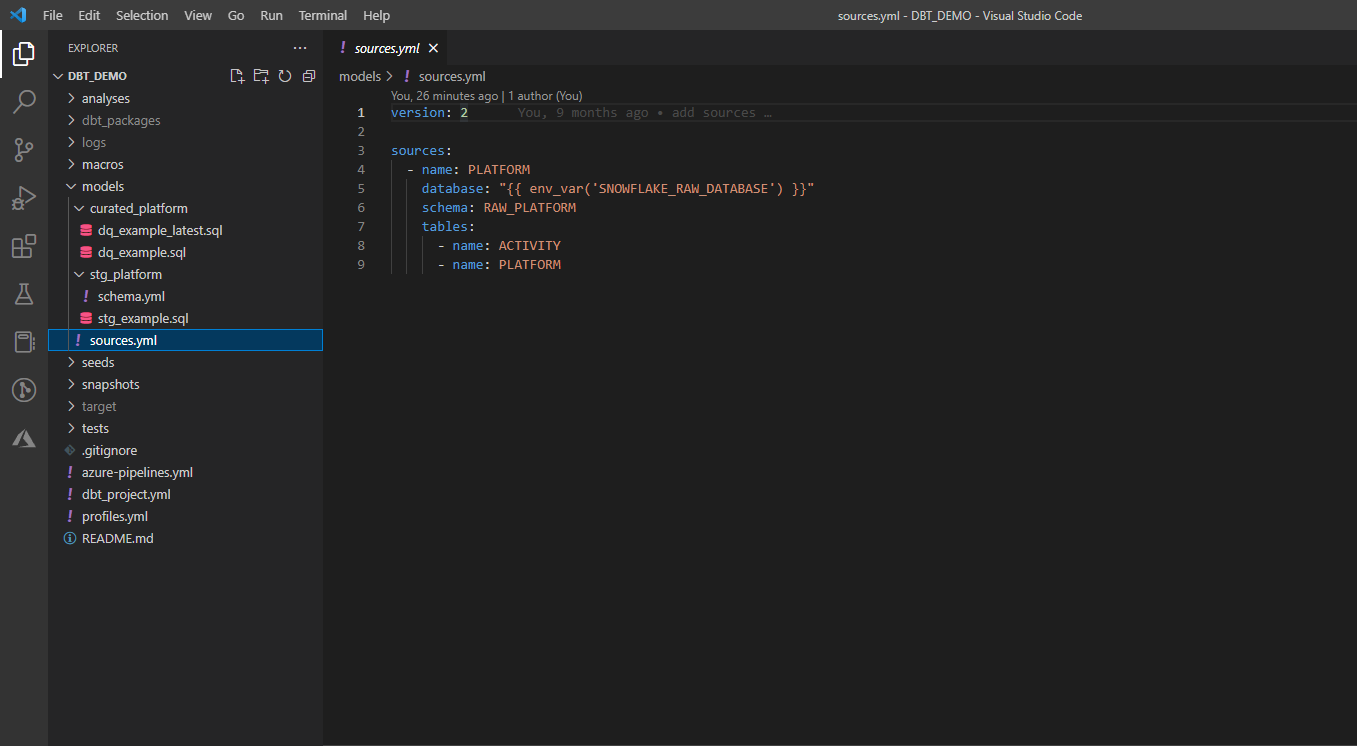
1. Define source tables.
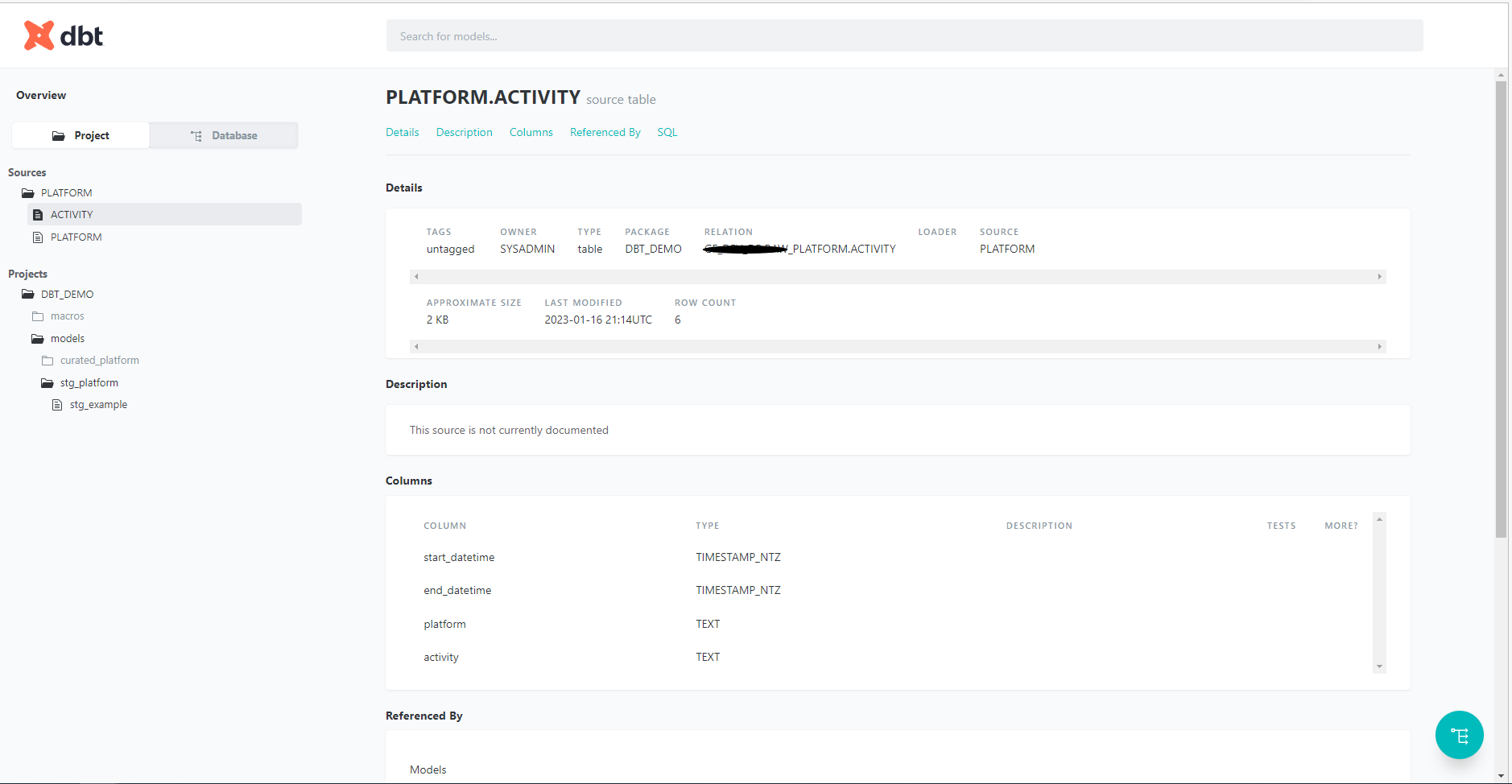
Tables used in DBT data processing as a source are defined in sources.yml file. You should provide information about database, schema and list the tables you are going to use in transformations. You can use either variables or environment variables to parametrize data sources. (ref: Database)
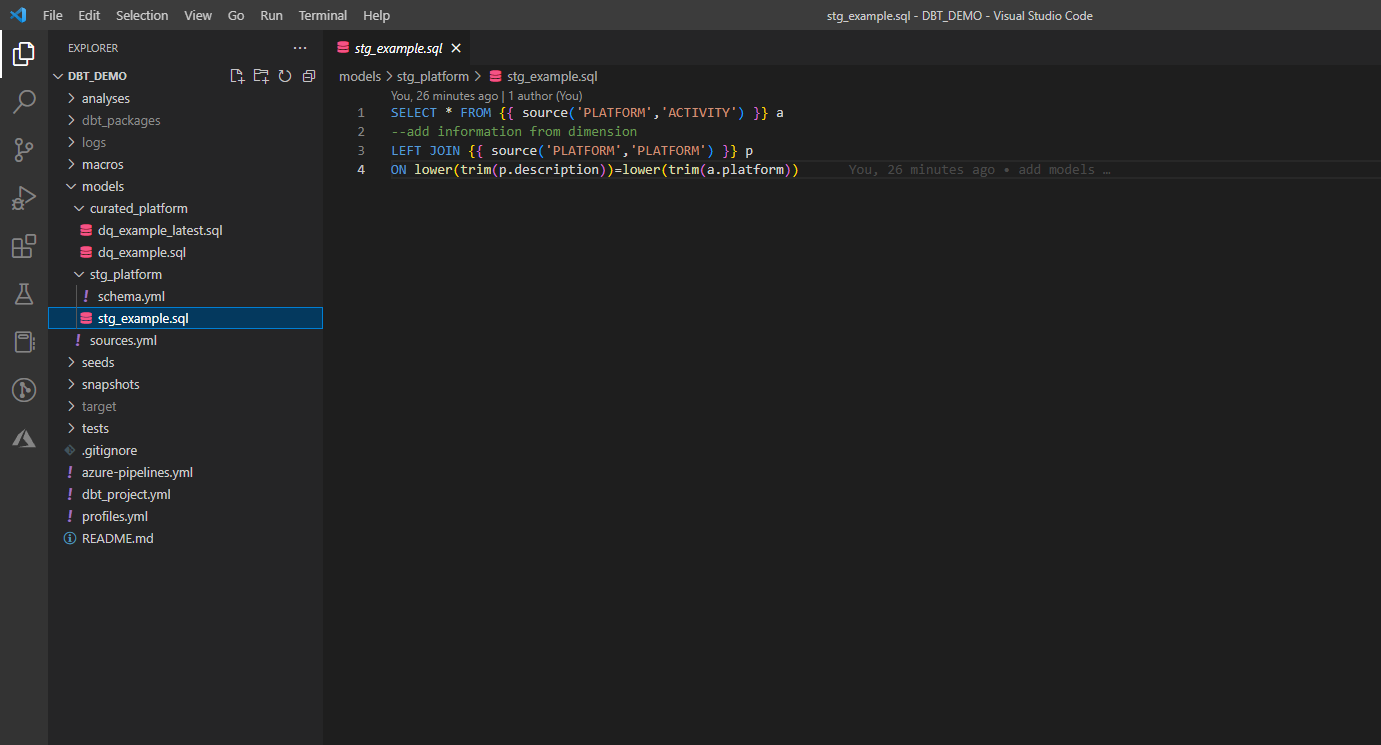
2. Create transformations (models).
Models are single .sql files, written as select statement. They can either refer to source table or another model. Latest DBT version allows to write python models too. Each model is either creating view or table depending on defined materialization type. Objects are created in database and schema defined in authentication configuration file (profiles.yml – database connection defines target database) and DBT Project configuration file (dbt_project.yml – folder structure defines target schema)
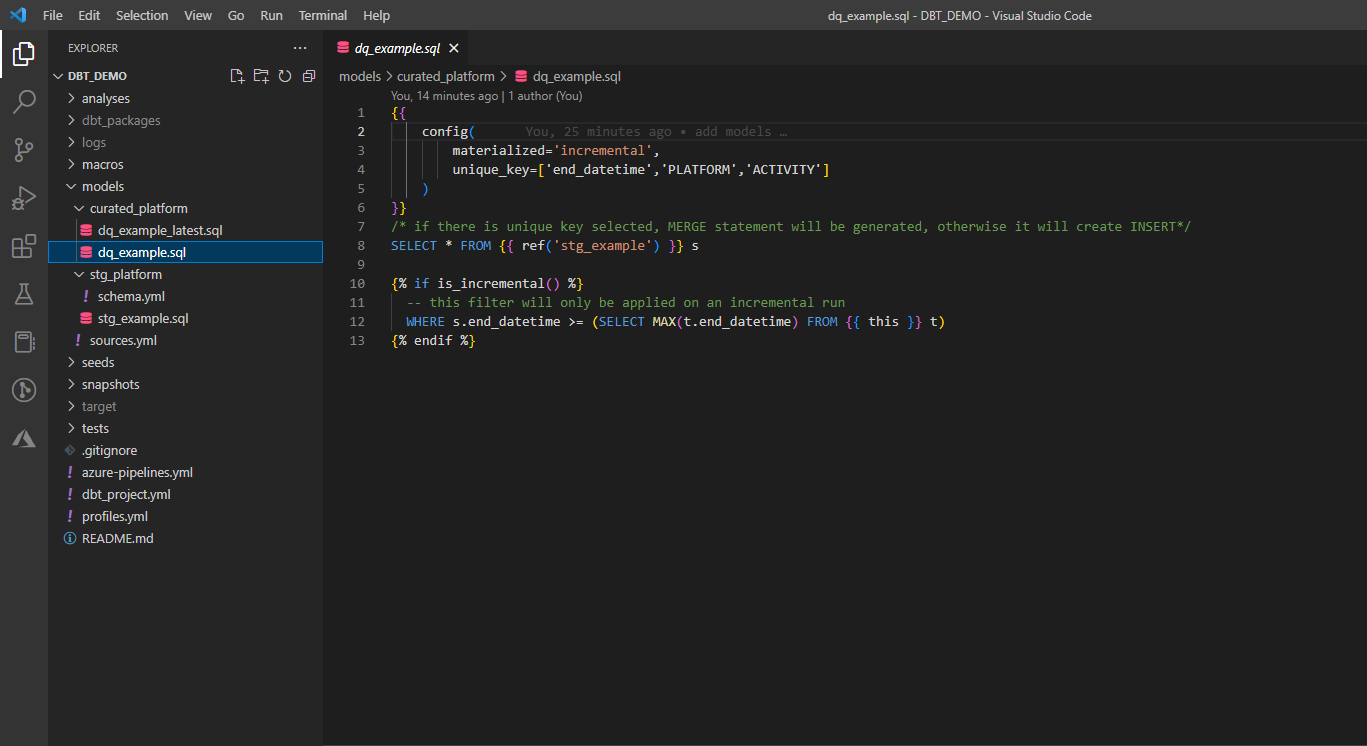
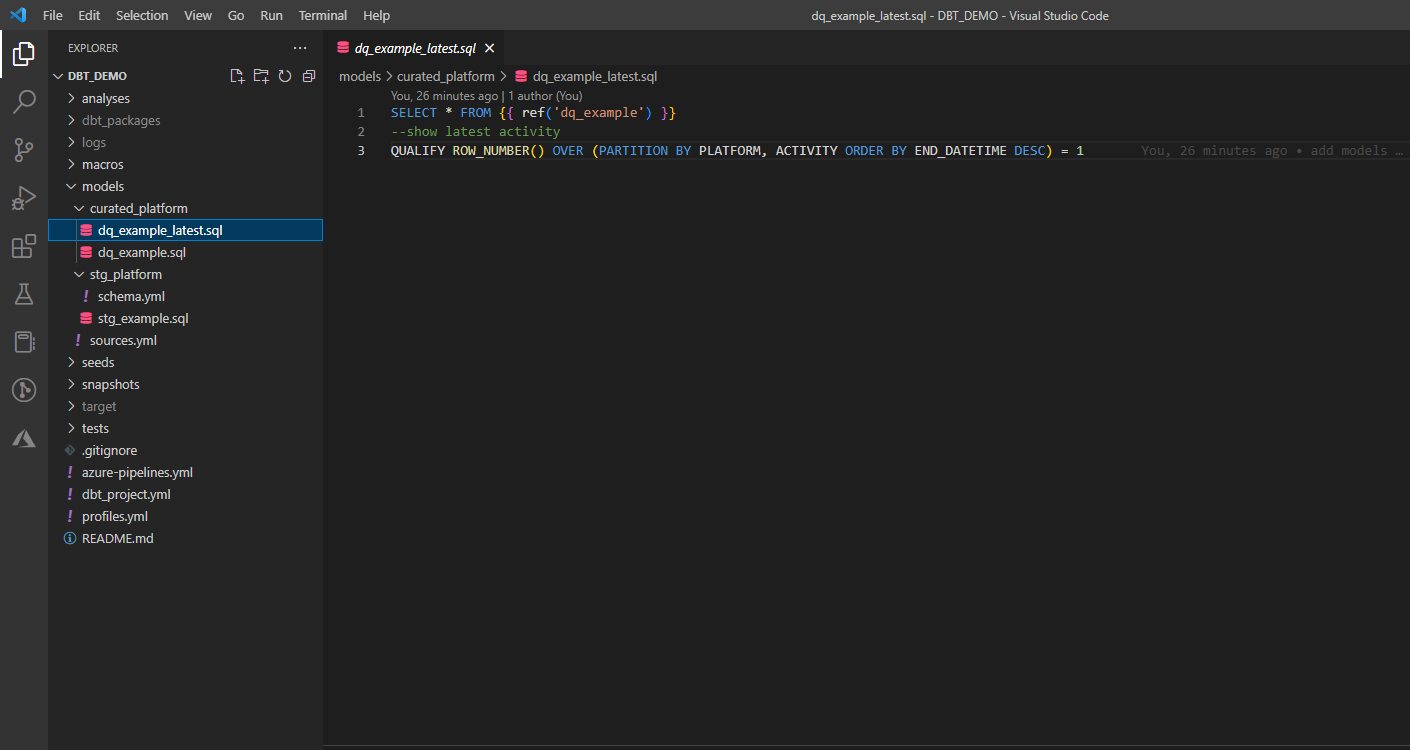
3. Add tests.
Tests allow to run sql queries evaluating data quality. Tests can be executed either by dbt test or dbt build command.
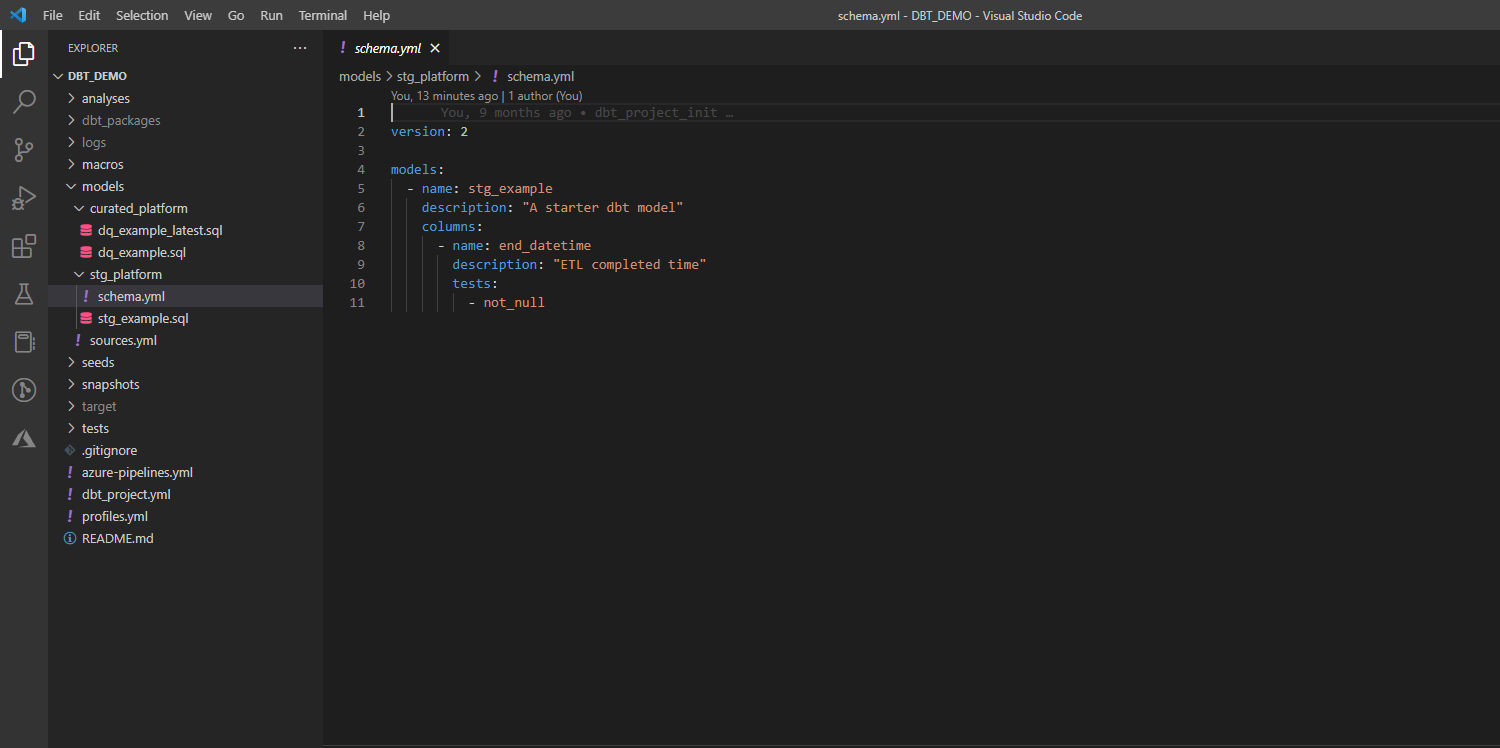
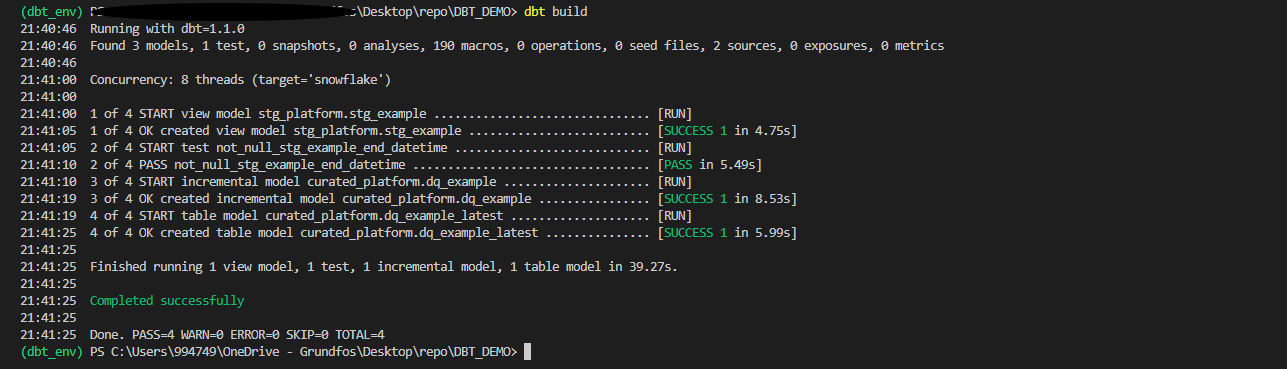
4. Execute DBT processing.
DBT is executed by simple dbt build, test or run command. DBT automatically evaluates model dependencies and orchestrates transformations.
5. DBT Documentation.
DBT autogenerates documentation too. Both table/model information and data lineage are available and can be published as website.