Would you like to start using Databricks or Synapse Spark Pool? Let’s review useful Pyspark commands used in Apache Spark DataFrames and transform data …
Documentation was divided into 7 components.
FILES – walk through folders and files in Databricks.
READ – load data to dataframe
TRANSFORM – basic transformation on dataframe
WRITE – write dataframe to destination folder
METASTORE– table, view registration in Databricks
DELTA – useful delta functionalities
OTHERS – schema, explain, partitioning etc.
Files section will allow to walk through folders and files in Databricks.
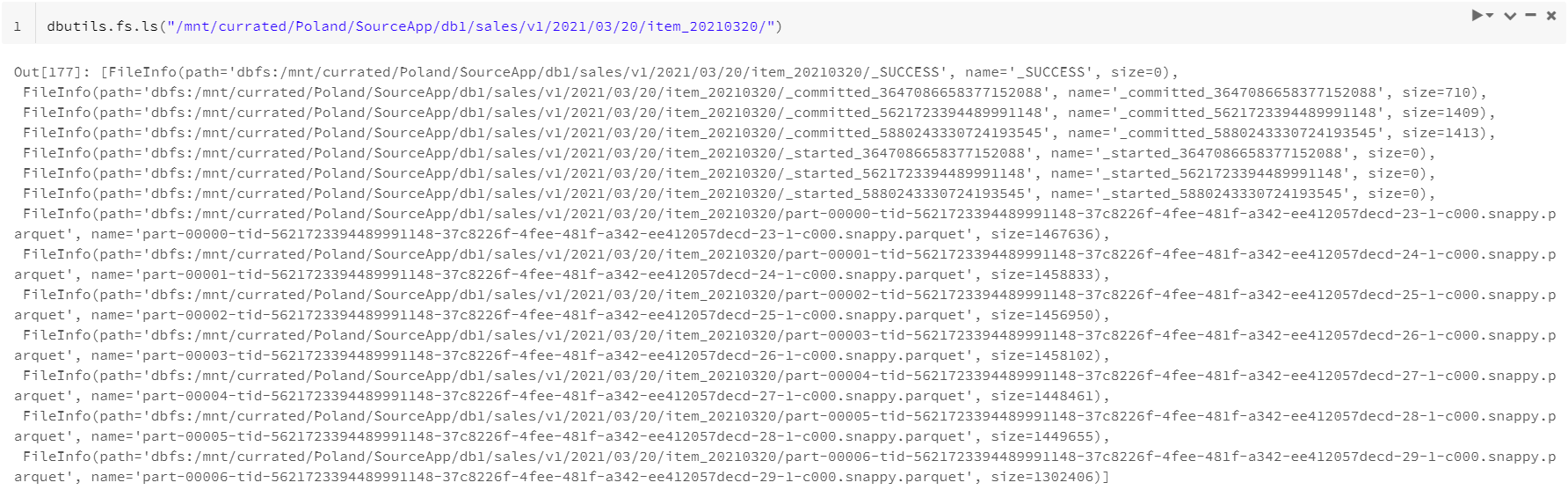
1. List files in folder
dbutils.fs.ls function allows to list all files in particular folder of mounted storage.
dbutils.fs.ls("source_path")
source_path – path of a file to be loaded
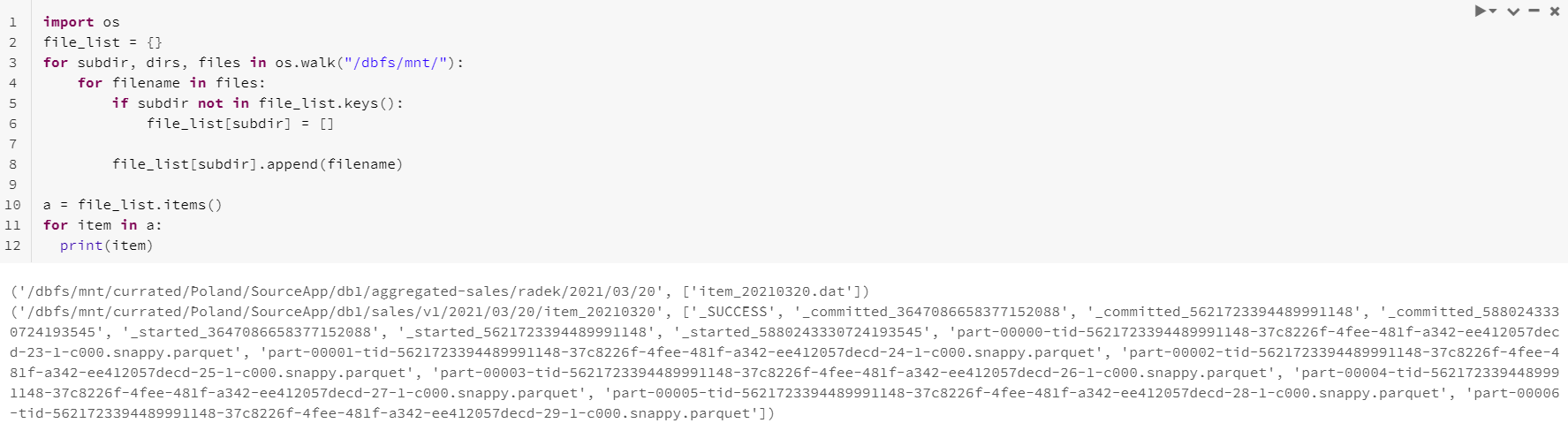
2. List all files in folder and all subfolders of mounted Storage
Following python script creates a list of files in folder and all subfolders of mounted storage
import os
file_list = {}
for subdir, dirs, files in os.walk("/dbfs/mnt/"):
for filename in files:
if subdir not in file_list.keys():
file_list[subdir] = []
file_list[subdir].append(filename)
mnt – name of mounted Data Lake
3. Remove files
dbutils.fs.rm function allows to remove files from particular folder of mounted storage.
dbutils.fs.rm("source_path", recurse=True)
Read section will allow to load data to dataframe.
1. Read file to dataframe
spark.read function allows to load data from storage to cluster memory.
df=spark.read.format("format").load("source_path")
source_path – path of file to be loaded(eg. /mnt/prd/bronze/dbr/training/2021/08/03/)
format – parquet, delta, csv etc.
2. Read table to dataframe
spark.table function allows to load data from Databricks table to cluster memory.
df=spark.table("schema_name.table_name")
schema_name – schema in Databricks
table_name – table in Databricks
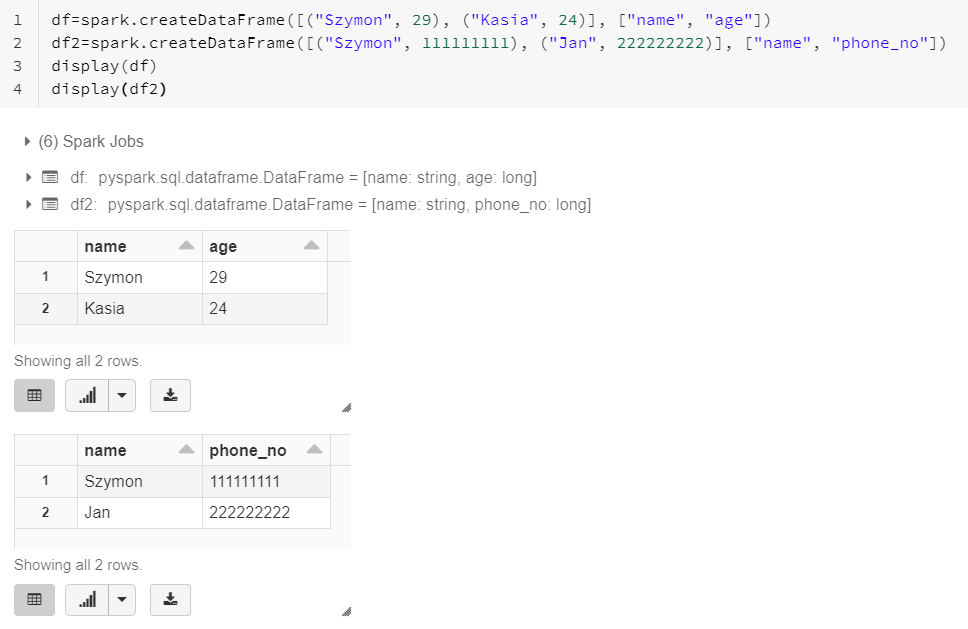
3. Create dataframe from values
df=spark.createDataFrame([("value1", value2), ("value1", value2)], ["column_name1", "column_name2"])
value1 – value for first column (string)
value2 – value for second column (numeric)
column_name1 – name of first column
column_name2 – name of second column
This section is about simple transformation that can be implemented in Databricks.
1. Filter
filter/where functions allow to filter data of dataframe. There are several ways described below to use filter/where functions.
df.filter(df.column_name=="value")
from pyspark.sql.functions import col
df.where(col("column_name")=="value")
df.where(col("column_name").isNotNull())
df.where((col("column_name")=="value") & (col("column_name2")=="value2"))
df.where((col("column_name")=="value") | (col("column_name2")=="value2"))
column_name – column that should be filtered
value – value that should be used in filter
& – AND
| – OR
![]()
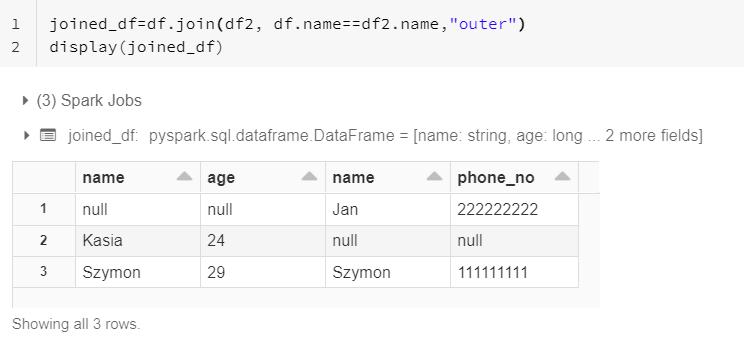
2. Join
join function allows to merge 2 dataframes into single one. There are 2 ways to join data depending if you want to show joining column values twice.
first_dataframe.join(second_dataframe, first_dataframe.column_name==second_dataframe.column_name, "join_type") first_dataframe.join(second_dataframe, ["column_name"],"join_type")
join_type – inner, left_outer, right_outer etc.
column_name – join column name
There are 5 types of joins
– the broadcast hash join (BHJ) – one small (less than 10 MB) and one larger dataset,
– shuffle hash join (SHJ),
– shuffle sort merge join (SMJ) – two large datasets a common key that is sortable, unique, and can be assigned to or stored in the same partition,
– broadcast nested loop join (BNLJ),
– shuffle-an-replicated nested loop join
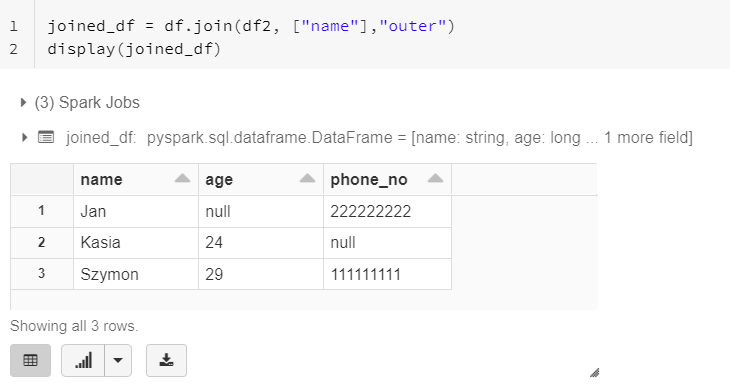
3. Add column
withColumn function allows to add new column to dataframe.
from pyspark.sql.functions import current_timestamp,lit
df.withColumn("alias_name",current_timestamp(),\
.withColumn("alias_name2", lit("test"))
alias_name- name of new column
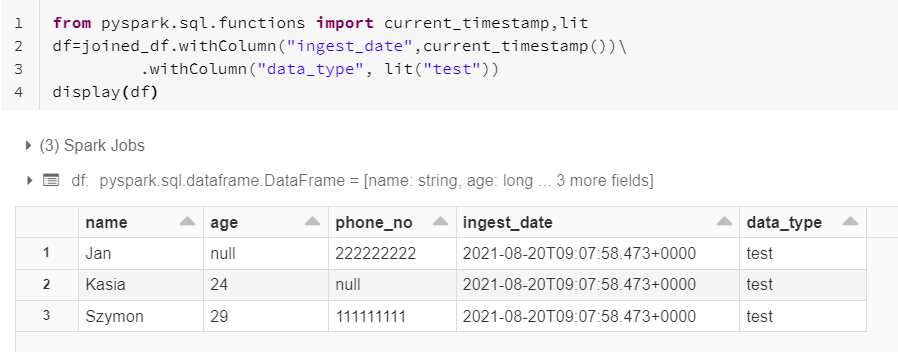
4. Case when
when/expr functions allow to add new column depending on different if logic.
df.select("column_name1", F.when(df.column_name2 > X, Y).otherwise(Z).alias(alias_name2))
from pyspark.sql.functions import expr
df.withColumn("column_name", expr("CASE WHEN column_name > X THEN Y ELSE Z END"))
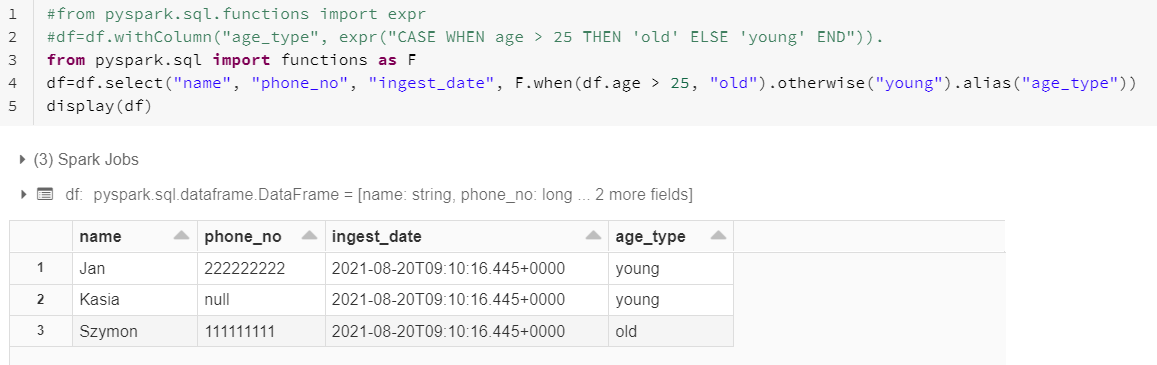
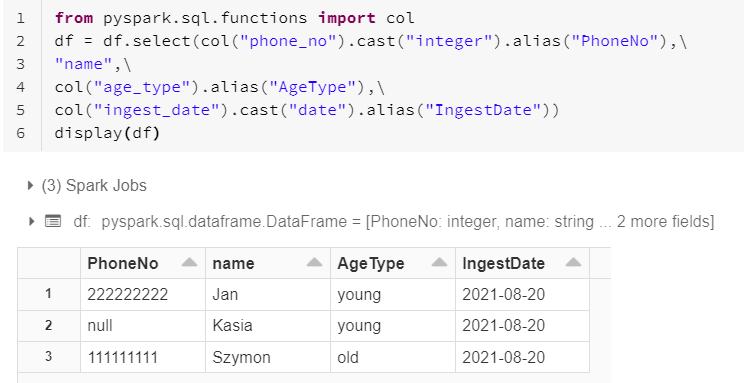
5. Select column
select functions allow to select interesting column from dataframe.
from pyspark.sql.functions import col
df.select(col("column_name").cast("type_of_column").alias("alias_name"),\
"column_name2",\
col("column_name3").cast("type_of_column3").alias("alias_name3")))
column_name – column that should be selected
type_of_column – type of transformed column
alias_name – new column name
Use col function if you want to easily change format or name of the column.
6. Drop column
drop function allows to drop not needed column from dataframe.
df.drop(df.column_name).drop(df.column_name2)
df.drop("column_name","column_name2")

7. Aggregate
groupBy function allows to aggregate measures on particular level.
df.groupBy.function(column_name)
from pyspark.sql.functions import function
df.groupBy("grouping_column_name")\
.agg(function("column_name").alias("alias_name"),\
function("column_name").alias("alias_name"))
grouping_column_name – column used in grouping
column_name – KPI used to aggregate
function – max, min, sum, avg etc.
alias_name- KPI alias name
.agg() aggregation function is used to to calculate multiple aggregations at the same time.

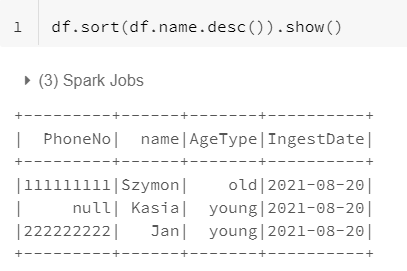
8. Sort
sort/order by functions allow to sort data either ascending or descending based on selected columns.
df.sort(df.column_name.desc())
df.sort("column_name", ascending=False)
df.orderBy(["column_name", "column_name2"], ascending=[0,1])
9. Remove duplicates
df.dropDuplicates() df.distinct()
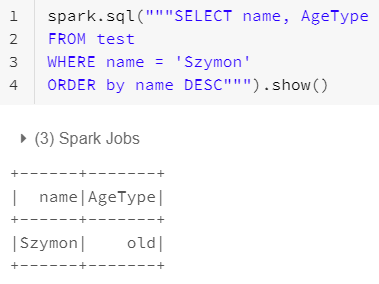
10. Spark SQL
spark.sql allows to type sql query based on registered tables or views in Databricks.
spark.sql("""SELECT column_name
FROM schema_name.table_name
WHERE column_name = 'ORD'
ORDER by column_name DESC""")
11. Datetime Functions
from pyspark.sql.functions import date_format, month, to_date, date_add
df.withColumn("date string", date_format("column_name", "MMMM dd, yyyy"))\
.withColumn("time string", date_format("column_name", "HH:mm:ss.SSSSSS"))\
.withColumn("month", month(col("column_name")))\
.withColumn("date", to_date(col("column_name")))\
.withColumn("plus_two_days",date_add(col("column_name"),2))
Write section will describe how to save transformed data to destination folder.
1. Overwrite, append
df.write.format("format")\
.mode("write_mode")\
.option("mergeSchema", True)\
.partitionBy("partitioned_column")\
.save("dest_path")
format – parquet, delta, csv etc.
write_mode – overwrite, append
dest_path – path were transformed data should be written
partitioned_column – column that should be used for partitioning
2. Merge (Delta)
deltaTable = DeltaTable.forPath(spark, "dest_path")
deltaTable.alias("t").merge(df.alias("s"), "s.ID=t.ID")\
.whenMatchedUpdateAll()\
.whenNotMatchedInsertAll()\
.execute()
dest_path – path of existing files (target) in Delta Lake
df – dataframe (source) that will be merged with target data
Metastore-defined table allows to read files using SQL.
1. Create table
create table statement allows to create table metastore based on existing files in Delta Lake
%sql CREATE TABLE dest_schema_name.dest_table_name (column_name column_type) USING DELTA LOCATION "dest_path"
dest_path – path of existing files in Delta Lake
dest_schema_name – schema in Databricks
dest_table_name – table in Databricks
2. Save as table
saveAsTable option allows to create table metastore in Databricks while saving file in Data Lake.
df.write.format(delta)\
.option("path",dest_path)\
.option("mergeSchema", True)\
.saveAsTable("dest_schema_name.dest_table_name")
dest_path – path were transformed data should be written
dest_schema_name – schema in Databricks
dest_table_name – table in Databricks
3. Register as view
createGlobalTempView statement allows to create view that is available for other users.
createOrReplaceTempView statement allows to create temporary view that can be used within the same session.
df.createGlobalTempView("schema_name.table_name")
df.createOrReplaceTempView("table_name")
1. Audit
history function allows to see summary of transaction log.
deltaTable=DeltaTable.forPath(spark,"path") deltaTable.history(no_records)
path – path of delta files
no_records – filter history of operations on delta files
DESCRIBE HISTORY schema_name.table_name LIMIT no_records
schema_name – schema in Databricks
table_name – table in Databricks
no_records – filter history of operations on delta files
2. Time Travel
restore functions allows to get old version of delta files.
deltaTable=DeltaTable.forPath(spark,"path") deltaTable.restoreToVersion(X)
path – path of delta files
X – version to be restored
%sql RESTORE TABLE schema_name.table_name TO VERSION AS OF X RESTORE TABLE schema_name.table_name` TO TIMESTAMP AS OF DATE
X – version to be restored
DATE – date of version to be restored
3. Files Retention
vacum function allows to remove old delta files from Storage.
VACUUM schema_name.table_name RETAIN X hours deltaTable=DeltaTable.forPath(spark,"path") deltaTable.vacuum(X)
1. SCHEMA DEFINITION
from pyspark.sql.types import *
schema = StructType([StructField("author", StringType(), False),
StructField("title", StringType(), False),
StructField("pages", IntegerType(), False)])
from pyspark.sql import SparkSession
schema = "'author' STRING, 'title' STRING, 'pages' INT"
2. EXPLAIN
explain function allows to see execution plan.
df.explan(mode="format_mode")
mode – simple, formatted, extended, codegen, cost
3. REPARTITIONING
Partitioning allows for efficient parallelism. A distributed scheme of breaking up data into chunks or partitions allows Spark executors to process only data that is close to them, minimizing network bandwidth. The size of a partition in Spark is dictated by spark.sql.files.maxPartitionBytes. The default is 128 MB. You can decrease the size, but that may result in what’s known as the “small file problem”—many small partition files, introducing an inordinate amount of disk I/O and performance degradation thanks to filesystem operations such as opening, closing, and listing directories, which on a distributed filesystem can be slow. Partitions are also created when you explicitly use certain methods of the DataFrame API. For example, while creating a large DataFrame or reading a large file from disk, you can explicitly instruct Spark to create a certain number of partitions.
df.repartition(X)
X – number of partitions